During the past two decades, Git, and its managed UIs like GitHub, GitLab and Azure DevOps has become standard and a de-facto synonym for Version Control. It is used for everything and everywhere. Including in the world of Data Engineering and ETL.
Across the industry, Data Engineering and Analytics teams have adopted Git to manage version control for Data Ingestion, ETL, and Transformation pipelines. However, many teams face operational and procedural challenges when applying Git effectively in these workflows.
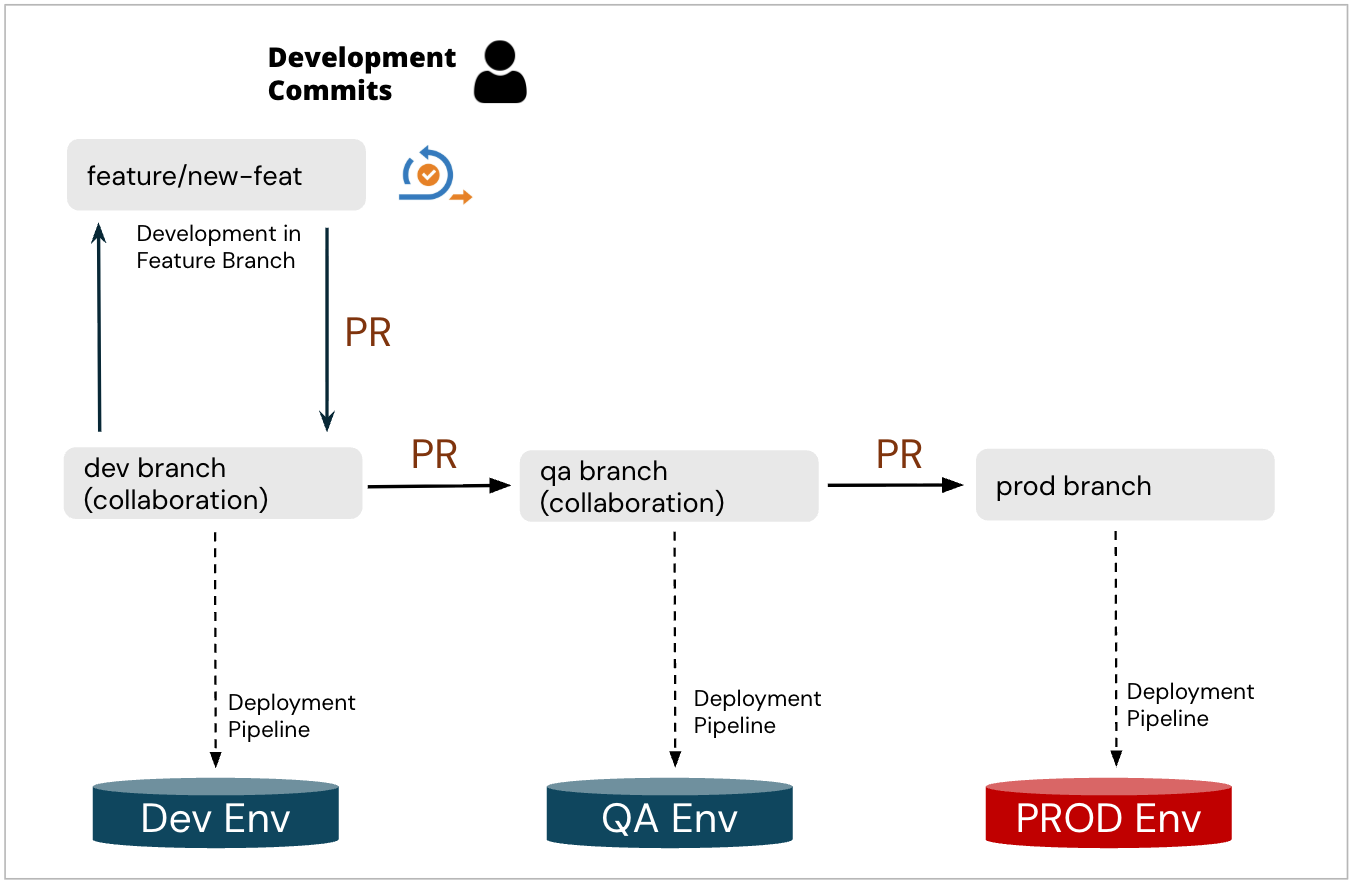
We observed many Enterprise Data Engineering teams often adopting the same naïve version of Git workflow (Git Flow), similar to the below:
They maintain multiple deployment environments, typically 3 (DEV, QA/UAT, PROD) and Git Branches for deployment to these respective environments.
Changes are promoted with Pull Requests directly between branches (dev → qa → prod) following some release cycle, sometimes aligned with scrum sprints.
Mature teams try to apply changes to “dev” branch via Pull Requests from a feature branch, if the underlying ETL tool(s) even support feature branches natively (such as Azure Data Factory, Databricks, DBT, etc.); When this is not the case with some legacy ETL tools, the process is often further simplified with all engineers directly contributing to collaboration ‘dev’ branch.
NOTE: the branch naming differs case by case, often one of the branches (lowest - dev, or highest - prod) is named ‘master’ or ‘main’ which does not change the essence of the end-to-end process.
NOTE: while technically this workflow is different from a canonic “Git Flow”, many organizations are still loosely referring to the process shown above often also calling it their “Git Flow”.
The All-or-Nothing Promotion Problem
Git was originally developed as a version control tool for Software Engineering (starting with Linux Kernel). In software engineering, different files — such as source code, headers, configuration files, and build scripts — are typically tightly coupled. To ensure the project remains functional and compilable, all files in a repository must be at the same revision.
For this reason, Git only supports full-repository merges between branches, that we typically do Pull Requests. This means all modified files in a feature branch are merged into the base branch as an "all-or-nothing" operation. While Git does support advanced merge scenarios, such as cherry-picking individual commits, it does not allow cherry-picking specific files when they were modified together.
Data Pipelines and ETL Jobs are often more independent and loosely coupled compared to source code files in a software application. While data pipelines and ETL jobs could be promoted independently, Git’s model does not support this flexibility.
With the naïve git flow (as shown above), teams often find themselves in situations where:
Collaboration “dev” branch and/or Test/QA branch has a mix of changes, some are fully tested and “ready-to-go”, while others still require further testing, fixes, approvals, or are dependent on external factors — making them not yet production-ready.
A Tech Lead needs to prepare a Pull Request for production — but it is picking up a mix of changes. This leads to a frantic effort to clean up the PR, involving commit-level cherry-picking which isn't always feasible if developers have intertwined changes across different pipelines, rollback changes, or other last-minute fixes to ensure only the right updates make it to production.
Often, unwanted changes are overlooked and get promoted to Production accidentally.
Teams utilize various approaches to dealing with the situation, including:
Enforcing strict rules of separating changes to different pipelines to different commits to leave more flexibility to Commits Cherry-Picking or Rebasing. However, in practice, individual contributors don't always follow these guidelines, which then makes the desired cherry-picking or rebasing impractical.
Adjusting their delivery cadence to follow very strict Sprint-based SCRUM schedule where literally all the changes are supposed to be -production-ready by the end of the sprint ensuring no incomplete pipelines remain in collaboration branches. However, in reality, half-baked pipelines still often end up in these branches.
None of these approaches work effectively and the challenges persist.
The alternative Git Workflow for Data Teams
Below, we present an alternative Git flow that we recommended to several data teams we've worked with. These teams successfully adopted the new process and found it to be a smoother, more effective approach for their needs.
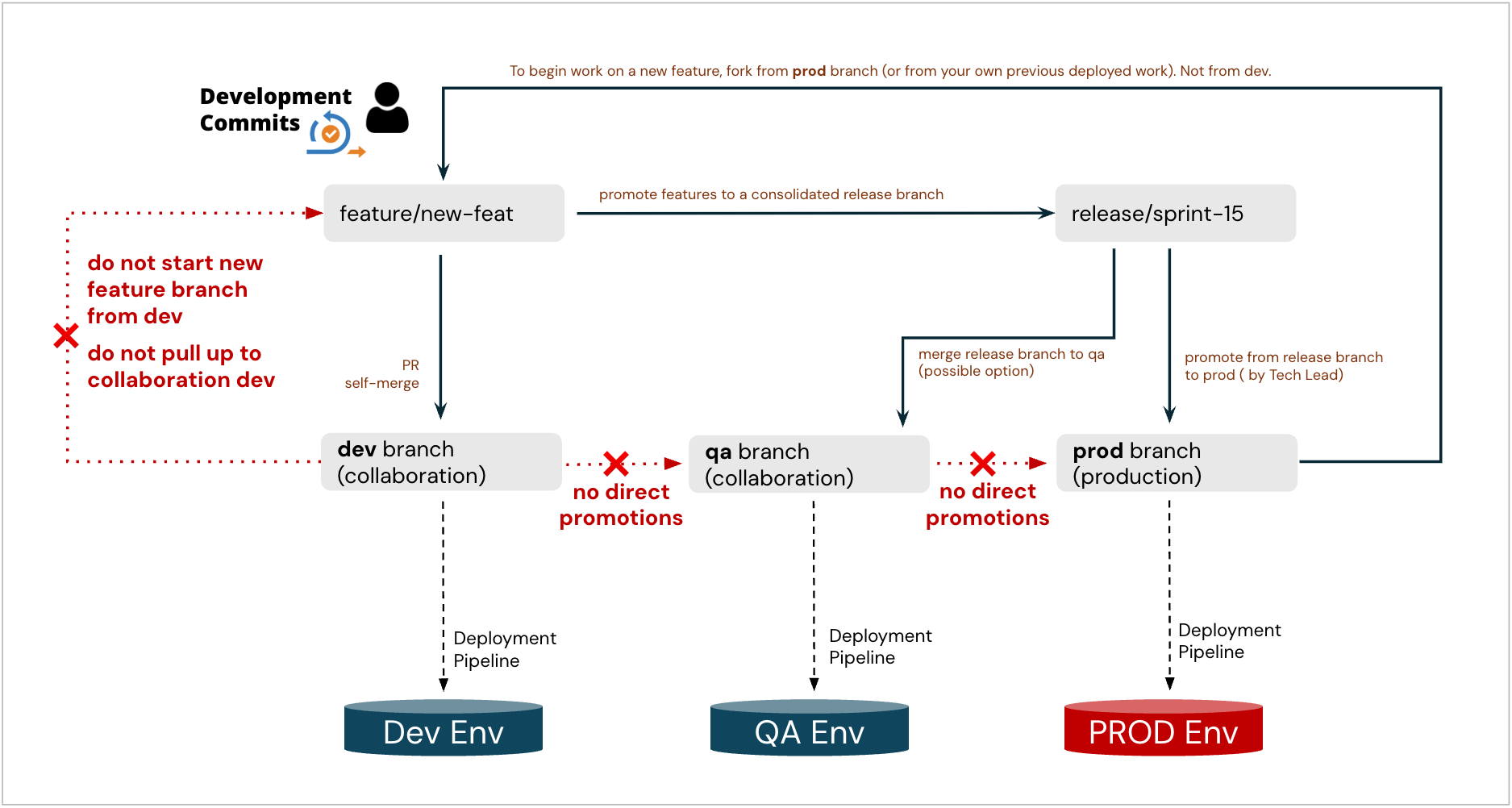
Full version of the process with release branches and QA of consolidated releases:
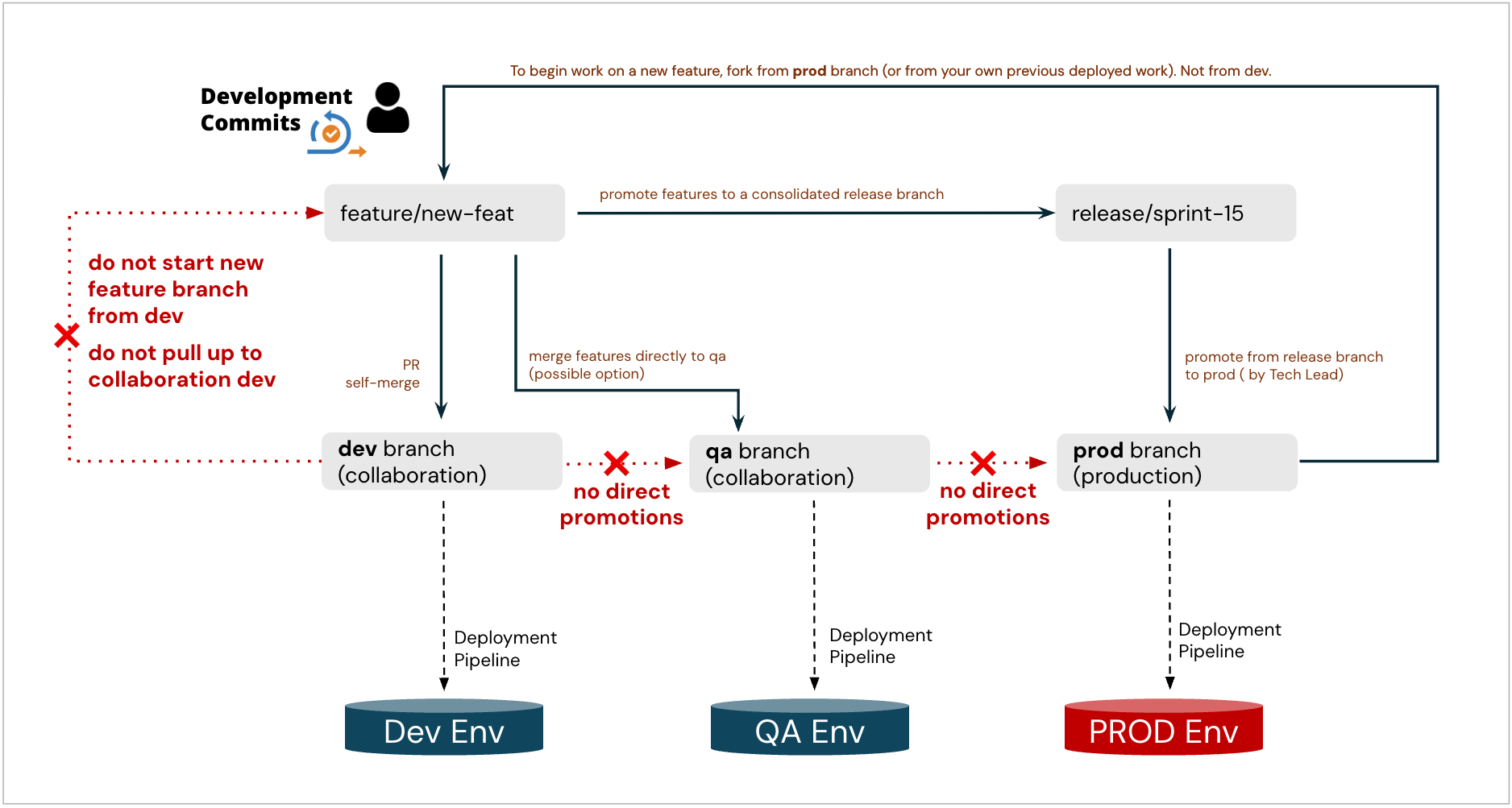
Another variation, promotion of individual features directly to QA:
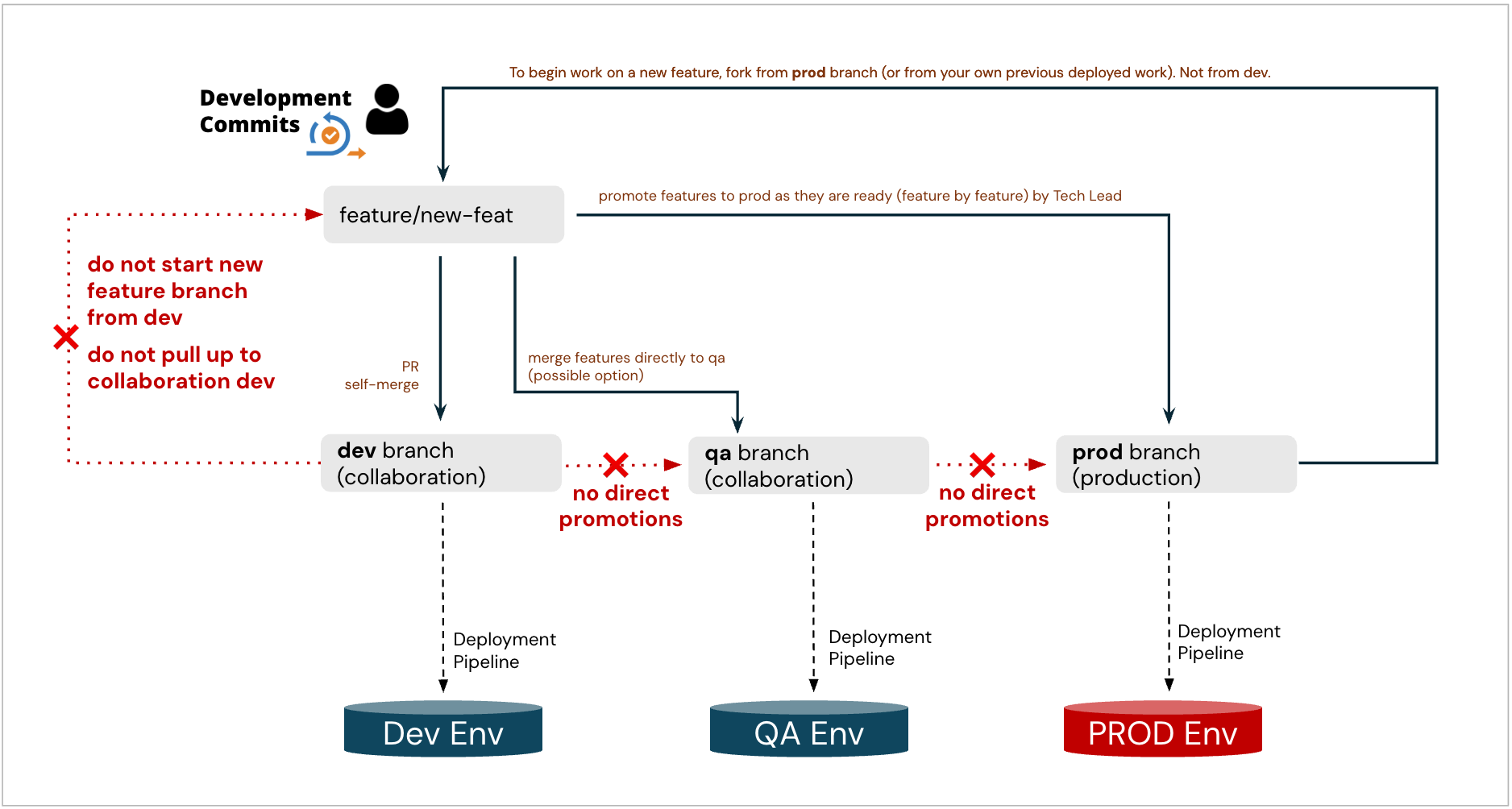
Simplified variation without consolidated release branch, pipeline-level features can be promoted directly to prod on a feature-by-feature basis:
Key highlights of the proposed Git flow for Data Engineering and ETL job/pipeline repos:
Recommended: clone new feature branches from prod after last sprint’s release (if applicable)
Sometimes Acceptable (case-by-case): developers may occasionally clone new feature branches from a recent feature branch, typically their own’s, as long as it is already promoted to production or is guaranteed to reach production. This approach can be useful when continuing improvements on the same pipelines.
Never start new feature branches by cloning from “dev” (or “uat”) collaboration (dumpster) branches, especially not from dev. Such a feature branch would ingest all previously non-released commits from these branches, including garbage - and then it cannot be promoted to Prod. If this happens by mistake, re-do the feature branch properly and clone it cleanly from prod, and reapply or cherry-pick the changes.
Try to make Feature Branches atomic in scope, aligning changes with affected pipelines and delivered stories. It is acceptable for a feature branch to include multiple small changes or even sprint stories — as long as there’s a clear understanding that all included changes will be deployed together and cannot be separated. It remains an all-or-nothing approach at the feature branch level.
Use Pull Requests to promote changes:
Promote feature to the “dev” collaboration branch. Developers manage and resolve conflicts as they arise. Typically, if any conflicts exist, they would transpire at this step.
Promote feature to “uat” collaboration branch, when ready for UAT
If the team prefers to consolidate all changes into Production Releases via Release Branches, this approach is encouraged but not mandatory.
Promote Feature to a Release Branch
Multiple features from different developers can be combined in one release branch as part of the preparation for a Production Release
Release Branch to “Prod” when the entire release is validated ready for prime-time deployment.
If the team is not doing consolidated releases, and instead wants to promote individual feature changes on a one-off basis (or as an exceptional promotion between large releases):
Promote Feature to a ”Prod” Branch directly
Never do full branch merges of “dev” to “uat”, or “uat” to “prod”
Only individual feature-level commits will make their way between environments (directly, or indirectly via a Release branch) once they are deemed production-ready. Not the entire collaboration branches.
It is understood that “dev” and “uat” collaboration branches (especially dev) will be accumulating commits at different stages of readiness, including many changes that were abandoned and never reached production — basically, garbage.
From time to time, perhaps at the beginning of certain Sprints when the situation is favorable, abandon and restart “dev” and “uat” collaboration branches by archiving them and restarting fresh branches from the current Production. Re-apply any outstanding feature branches that were still work-in-progress at that time.
In your managed git environment (GitHub or Azure DevOps), set repository default branch to prod (not dev)
This practice ensures that new developers, or engineers from other adjacent teams, always start with a clean, and established version of the code by default, rather than a mix of production-ready and garbage code from lower-level collaboration dumpster branches
It will also further reinforce the concept that new feature branches must be cloned from ‘prod’ not from dev
We do not recommend having any “main” or “master” branches in Data Pipelines Git repositories at all. These branch names often cause persistent confusion whether ‘main’ branch represents the ‘Development’ or ‘Production’ environment. The easiest way to avoid this confusion is to avoid having a ‘main’ (’master’) branch at all, and instead name branches according to the data environment they truly represent: dev,qa and prod. prod should be the default branch in the repository.
Takeaway and Disclaimers
Git is a very powerful and flexible tool that supports great flexibility in choosing the right flow (process) suited to the for a specific needs, processes, and culture of each engineering team.
The proposed Git workflow may not be a perfect fit for each and every Data Engineering team, and has its own shortcomings and limitations. For example, it does not fully align with advanced data engineering practices with modern tools like DBT which encourages true CI/CD with repository-wide tests being run for PRs, deploying temporary PR-level schemas, etc. But may legacy data integration tools do not provide such levels of CI/CD sophistication anyway.
We have worked with several Enterprise Data & Analytics teams that initially struggled with the naive Git workflow - one that was historically adopted “by default”, that actually benefitted from switching to the alternative workflow presented here.
This is why we decided to share this observation with you - so that other teams facing similar challenges can explore an alternative Git workflow that may better fir their needs.






.jpg)


