

Financial institutions specialized in capital markets such as hedge funds, market makers and pension funds have long been early adopters of the latest analytical techniques, and novel alternative data. Often, in this highly competitive industry, the winners outperform because they can more quickly summarize and act on a wider range of data to “get alpha”.
The maturation of Generative AI (Gen AI) has not gone unnoticed by the whole of the financial services industry and the data dichotomy that long existed between the buy side and sell side is closing fast. Leaders have recognized the game-changing value large language models (LLMs) and AI technologies can bring to augment their financial analyst teams. With no shortage of enthusiasm, many have already made investments in initial proofs of concepts and limited pilots, which are typically born out of their respective data science departments. Today, the battle to “alpha” no longer solely resides in who would be sourcing the right information earliest, but also who can be first to translate their technical pilots into enterprise ready applications for business users to trust and act upon.
Ready to make further investments, leading financial organizations are working towards operationalizing these models with interactive visual experiences specifically tailored for financial analysts. For forward thinking financial institutions, they are seeking to align these new tools with their existing analytics platform investments, and governance standards. They are looking to deliver this capability cost-effectively in a manner that avoids vendor lock-in and provides them with the necessary flexibility to adopt best of breed capabilities and new AI standards perpetually developed and released by the open-source community.
There are three main areas to consider when choosing to build or buy a production-quality trustable GenAI for financial valuations:
For those “seeking alpha”, comprehensive, clean, discoverable and trustable data is an indispensable starting point. The Lakehouse Platform provides the foundation to make this possible, while providing the flexibility and control necessary to adapt to the rapidly evolving field of Gen AI.
Capital markets teams frequently subscribe to and manage a variety of market research and analytical software point solutions. Although invaluable for financial analysts, these tools can feel disconnected from the wider array of data curated by their IT data team peers. This situation can lead to redundant parallel storage, and analytics systems and activities outside of the organization’s primary cloud environment.
A data driven approach for building these applications is crucial, but a solution that is not aligned with the wider organization can lead to Gen AI solutions stalling in the pilot phase. One large pension fund rejected a point solution, as it would have required the duplication of infrastructure and data on a parallel cloud. Ideally, a centralized repository built on open storage formats provides the widest possible array of input documents to the Gen AI model. There may already be a wealth of public, owned and purchased documents and data for you to leverage, while avoiding costly data duplication and redundant processes.
The wider the array of documents, the more complete coverage and greater number of insights the model can help to reveal.
Some documents to consider exposing to your Gen AI financial valuation solution include:
A medallion architecture pattern is the preferred approach for ingesting these documents into the analytics platform. Data engineers can build automated pipelines for the most common types of documents and data. For ad hoc document ingestion, consider exposing a graphical user interface for financial analysts to use directly as shown below:

The RAG (Retrieval-Augmented Generation) workflow or chain is at the heart of the back end of any Gen AI based solution. These workflows contain the instructions that marry your own private data and organizational standards to your chosen LLM(s). The RAG architecture pattern means you are making queries to the pre-trained LLM using your own proprietary data in any format, as opposed to relying on the information provided to the LLM during training. This approach aligns with the “Data Intelligence Platform” strategy that understands the semantics of your data.
For software developers, the RAG pattern is somewhat analogous to coding with APIs - enriching requests with a service to other pieces of software. For the less technical, imagine the RAG pattern as one where you ask a very smart friend for advice and equip them with your own personal notes, and send them to the library. Before they go, you “prompt” them to limit the scope of their response, while giving them the freedom to provide their best analytical reasoning in their answer.
The RAG workflow is what contains the instructions for this handoff, which can be tailored to suit your unique data sources, bespoke calculations, guardrails and unique enterprise context, because a competitive advantage always lies in using your proprietary data.

Not ready to make an investment in a tailored RAG workflow? Laying the groundwork with an open and customizable architecture will be important to help build trust within your organization before moving any solution to production. Visibility and control over your RAG workflow helps to enhance explainability and trust. This was important for a large private equity investor, who rejected a commercial Gen AI solution because they were unable to successfully reproduce the identical results when using the same inputs week-over-week; the underlying model and/or RAG workflow had changed, with no way of rolling back to a previous version.
Although commercial Gen AI models initially attracted the greatest fanfare and media attention, open source alternatives have been catching up and are continuing to evolve. Alongside tuning and custom RAG workflows, open source models represent a compelling case versus commercial alternatives when evaluating performance and cost effectiveness.
A flexible and transparent solution lends itself the versatility to easily swap in the latest open source model. For example, Gen AI applications built with customizable RAG workflows were immediately able to take advantage of Databricks’ open source DBRX model, which has outperformed established open source and commercial models. This is only one recent example, as the open source community continues to relentlessly release new powerful models quarter after quarter.

As Gen AI application adoption increases for financial organizations, the cost of these solutions will be placed under growing scrutiny over time. A proof of concept which uses commercial Gen AI models may initially have an acceptable cost with only a handful of analysts using the solution for a limited time. As the volume of private data, response time SLAs, complexity of queries and number of requests increases, more cost effective alternatives will warrant exploration.
The true costs for a team performing financial analysis will vary based on the demands users place on them. At one large financial institution, they found a response time of over two minutes acceptable for a limited pilot, but looked to increase compute capacity when considering a full production rollout with a SLA for outputs to be partially generated in under a minute. A flexible solution that offers the choice of the latest open source models and underlying infrastructure to achieve the required cost-performance balance for different types of use-cases provides cost effective scale that is essential for financial institutions.
The choice between open source LLMs and OpenAI depends on your specific needs, resources, and constraints. If customization, cost-effectiveness, and data privacy are your priorities, open source LLMs might be a better choice. If you require high-quality text generation and are willing to bear the costs, commercial offerings could be the right option. The most important factor in choosing a platform that gives you all the options and future proofing your architecture to be flexible based on the rapid changes in the technology. This is the unique offering of Databricks Intelligence Platform, which provides full control irrespective of the level of customization and complexity you require as summarized below:

Pre-training
Training and LLM from scratch (with or without unified tools like Mosaic AI)Fine-tuningAdapting a pre-trained LLM to specific datasets or domains such as financial valuations or comparative analysisRetrieval Augmented Generation (RAG)Combining and LLM with enterprise data such as public and private financial reports, transcripts and alternative financial dataPrompt EngineeringCrafting specialized prompts to guide LLM behavior, which can be static reports, or presented as part of a visual exploration tool for financial analysts
Once your public and private financial documents are ingested and a RAG workflow is configured with your enterprise context, you are ready to explore model deployment options, as well as exposing the model to financial analysts.
For deployment, Databricks offers a variety of current and preview features, which enable not only a successful initial deployment, but also the right tools to continuously monitor, govern, confirm accuracy and scale cost effectively over time. Key deployment related capabilities include:
When combined, these features and tools allow for data scientists to more easily react to feedback from financial analysts. With an increased understanding of model quality, the model’s helpfulness, relevance and accuracy improves over time, leading to faster and more impactful financial insights.
Financial analysts require a visual way to interact with Gen AI models that aligns with the demands of their daily duties. Valuations and comparative analysis is an investigative and iterative process, and requires a way of interacting with the model that can keep up the pace. The interactive nature of the experience between financial analyst and model includes requests to elaborate specific paragraphs of a generated financial summary, or to prepare citations and references.
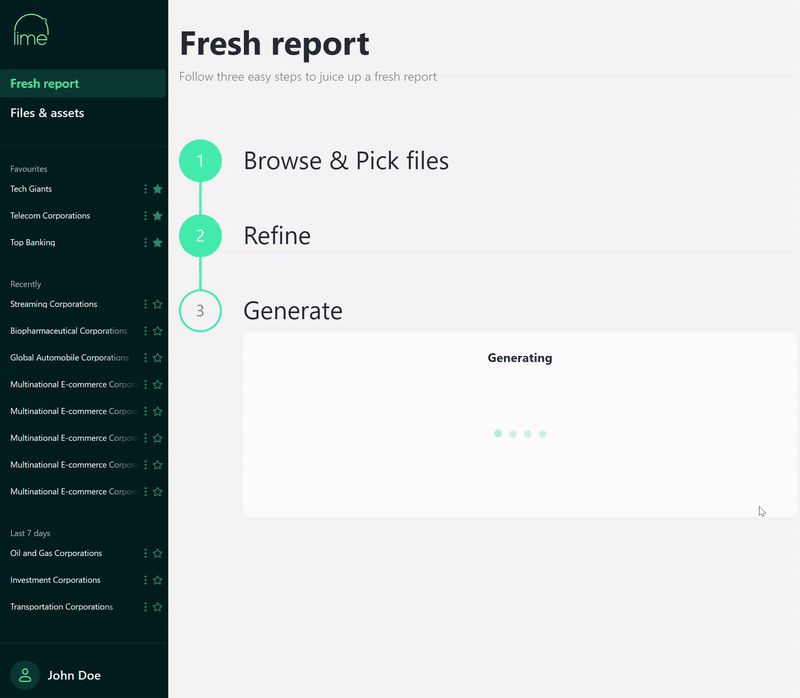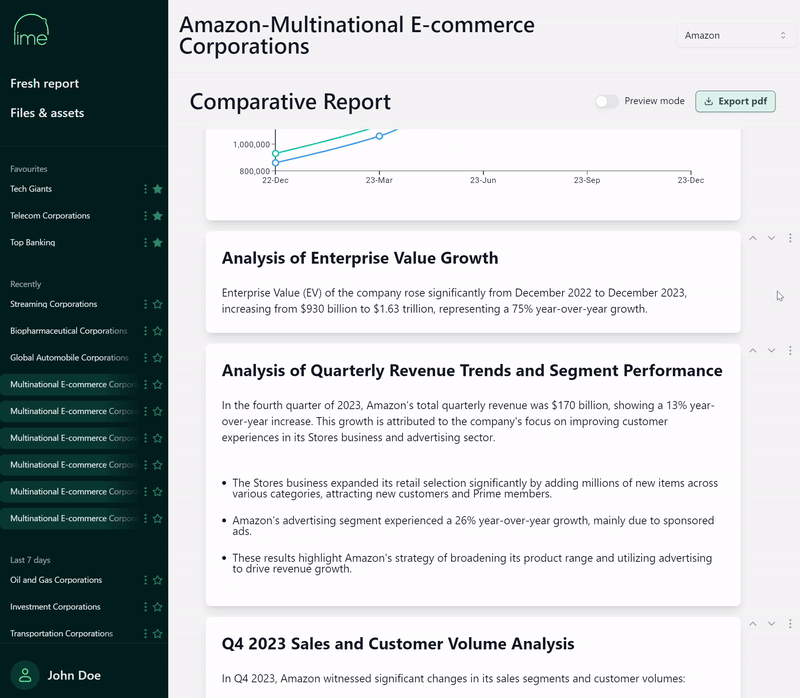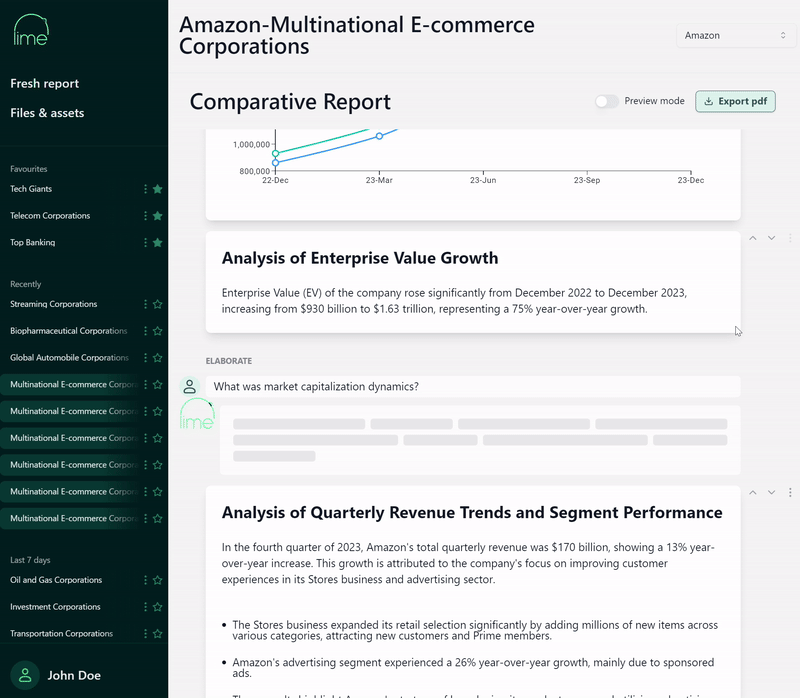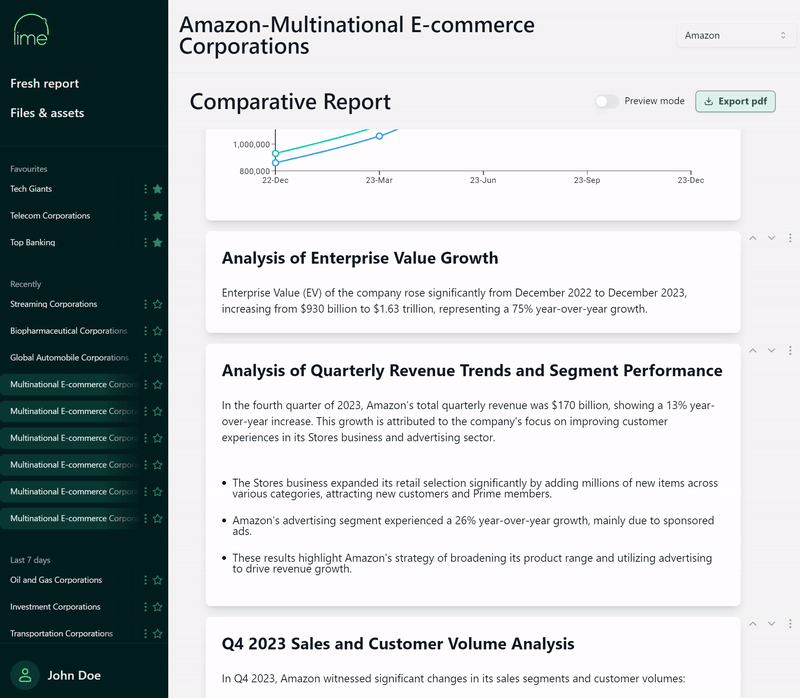
T1A, a Databricks partner, has developed Lime for this purpose. Lime offers a user interface designed specifically for financial analysts, which is powered by Databricks and is aligned with the Gen AI principles outlined in this article. In the below example, we can see an LLM generated report and the ability for analysts to elaborate paragraphs via a point-and-click experience.

Analysts are able to produce summaries for individual equities, as well as combined reports for comparative analysis. Using the chat and dynamic report interface, they can make follow-up inquiries such as “Why did the EBITDA change during the most recent period?” or “What factors might affect enterprise value over the next 12 months?”.
The interface includes opportunities for analysts to provide ratings on the quality of paragraphs, charts and elaborations as they work. In addition to providing an additional layer of quality control, this loop provides valuable feedback, which can provide a type of reinforcement learning that leads to changes to the RAG Workflow and model tuning. The more financial analysts use the solution, the more it reflects your organization’s unique context and the greater the strategic advantage.
The road to seeking alpha is paved with the right Gen AI infrastructure. It starts with an ingesting framework that embraces open storage standards that is shared across the organization and avoids duplication of financial documents. Growth and strategic differentiation occurs with on-going investment into RAG Workflows that understand your enterprise context and is understandable, and repeatable. Next, deploying the solution in a cost effective manner that leverages the latest open source models is required as you continuously monitor for quality and accuracy. Finally, layer on a user interface to ensure on-going engagement and adoption by financial analysts.






{kind=link}